Google Colaboratory上でKerasを使って画像認識をやってみた

はじめに
どうも、こじまるです。
前回Webスクレイピングのプログラムを作成していたら、AIを使った株価予測などもしてみたいなと思い、Google Colaboratoryを使ってみることにしました。今回は、Google Colaboratoryの利用方法とAIで画像認識をやってみたことについて記事にまとめております。
対象読者
- AI初心者の方
- Google Colaboratoryを使ってみたい方
- Kerasを使ってみたい方
この記事を見てわかること
- Google Colaboratoryの使い方
- Kerasでの画像認識の実装
Google Colaboratoryとは
Google Colaboratoryは、Googleアカウントを持っているユーザが無料で使用できるpythonの実行環境です。その環境では、機械学習を行う上で必須になってくる
- プログラムの実行環境
- GPUなどの資源
を無料で使用することができます。
個人で機械学習を行うための資源を用意しようと思った場合、NVIDIA(https://www.nvidia.com/ja-jp/)といったGPUを販売しているメーカーから購入する必要があるので、その実行環境が無料で手に入るというのは本当に凄いですね。
Google Colaboratoryの始め方
Google Colaboratoryは、Googleアカウントでログインし、サイト(https://colab.research.google.com/?hl=ja)にアクセスすることで始めることができます。まず、ノートブックを新規作成をクリックします。

新しいノートブックが作成されます。

pythonが実行できることを確認するために、Hello Worldを出力させてみます。スクリプトを入力し、エディタの左側の矢印ボタンを押下します。

スクリプトが実行され、Hello Worldが出力されました。


CIFAR-10 画像認識
CIFAR-10とは
CIFAR-10(CIFAR-10 and CIFAR-100 datasets)とは、画像認識などで使用されるデータセットになります。CIFAR-10のデータセットは、訓練データ : 50000枚、テストデータ : 10000枚で構成されており、下記のような10種類のクラスで構成されています。

実装
モデルの作成
今回はCNN(Convolutional Neural Network)を使用します。CNNとは、畳み込み層とプーリング層から構成されるNeural Networkになります。CNNに関しては詳細に説明しないので、必要であれば、下記のサイトを参考にしてください。
qiita.com
今回使用するネットワークは、Krizhevskyらの論文(https://dl.acm.org/doi/10.1145/3065386)で記載されていますネットワークを参考に作成しています。パラメータは筆者の経験と数回のチューニングを行った結果より決定しました。
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_4 (Conv2D) (None, 30, 30, 32) 896 _________________________________________________________________ activation_7 (Activation) (None, 30, 30, 32) 0 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_5 (Conv2D) (None, 15, 15, 64) 18496 _________________________________________________________________ activation_8 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 15, 15, 64) 36928 _________________________________________________________________ activation_9 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 15, 15, 64) 36928 _________________________________________________________________ activation_10 (Activation) (None, 15, 15, 64) 0 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 64) 0 _________________________________________________________________ dropout_2 (Dropout) (None, 7, 7, 64) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 3136) 0 _________________________________________________________________ dense_3 (Dense) (None, 1024) 3212288 _________________________________________________________________ activation_11 (Activation) (None, 1024) 0 _________________________________________________________________ dropout_3 (Dropout) (None, 1024) 0 _________________________________________________________________ dense_4 (Dense) (None, 1024) 1049600 _________________________________________________________________ activation_12 (Activation) (None, 1024) 0 _________________________________________________________________ dense_5 (Dense) (None, 10) 10250 _________________________________________________________________ activation_13 (Activation) (None, 10) 0 ================================================================= Total params: 4,365,386 Trainable params: 4,365,386 Non-trainable params: 0
実行結果
テスト結果は下記のようになりました。精度も0.80とそれなりに高い値が記録されています。
loss : 0.6048096418380737 accuracy : 0.8062000274658203
学習の推移と誤差は下記の通りです。


50epochの学習には大体200s(4s x 50epoch)程で完了しました。
Windows タスクスケジューラによるpythonスクリプトの自動実行

はじめに
どうも、こじまるです。
Webスクレイピングで高配当株 スクリーニング自動化ツールで、Windowsでpythonスクリプトを自動実行する方法を調査しました。今回はその設定方法について説明します。
タスクスケジューラを使用した自動実行
タスクの作成
筆者は、WindowsのPCを使用しているため、自動実行にはタスクスケジューラを使用します。画面右側の基本タスクの作成を選択します。

タスクの名前を入力します。

平日のみの実行が必要なので、毎週を選択します。

月曜日から金曜日のチェックボックスをチェックします。

プログラムを実行したいので、プログラムの開始を選択します。

入力フィールドに下記の情報を入力します。

完了の押下でタスク作成が完了します。

タスクスケジューラの設定手順は下記の記事を参考にさせていただきました。
www.atmarkit.co.jp

Webスクレイピングで高配当株 スクリーニング自動化ツールを作成した

どうも、こじまるです。
先日から高配当株投資を始めました。毎日株価をスクリーニングツールなどで確認しているのですが、スクリーニングツールで検索条件を設定して検索作業をするのが面倒です。そのため、スクリーニング条件と一致する株価情報を配信してくれるツールを作成しようと思いました。
はじめに
対象読者
- Webスクレイピングを始めたいと思っている方
- 高配当株のスクリーニングツールに興味がある方
この記事を見てわかること
- Webスクレイピングの事前準備、実施方法、実装方法
スクリーニング条件
私が高配当株の購入をするための目安にしているスクリーニングの条件は、下記になります。
この中でも、1.配当利回り、6.配当実績(増配傾向)を最も重要視しています。
こちらのスクリーニング条件は、こびと株さんのブログを参考に決定しました。
diamond.jp
調査
調査の進め方は、下記の記事を参考に調査を進めました。詳しく知りたい方は確認してください。
services.sms-datatech.co.jp
プログラムで株の情報を取得する方法
プログラムで株の情報を取得する方法として、下記の2通りの方法があります。
Webスクレイピングが禁止されているにも関わらず、それを実施してしまうことは問題になります。事前に情報提供元に確認するようにしましょう。
APIの利用
情報提供元がAPIを提供している場合には、それを活用した方がいいです。
株価の情報が取得できるAPIとして、下記が見つかりました。
・Yahoo financial API (yahoo-finance-api2 · PyPI)
・Alpha Vantage (Free Stock APIs in JSON & Excel | Alpha Vantage)
上記のAPIを確認しましたが、株価の情報は取得できましたが、配当金情報の取得は出来ませんでした。APIを公開しているサービスの情報は下記を参考にしました。
blog.codecamp.jp
Webスクレイピングの利用
APIが利用できない場合には、Webスクレイピングの利用を検討します。ただし、Webスクレイピングは情報提供元が禁止している場合もありますので、事前に確認が必要です。
Webスクレイピングが可能かどうかは、robots.txtを確認することで判断できます。たいていは、https://minkabu.jp/robots.txtのようにFQDNの直下にあります。robots.txtには、Webスクレイピングを行うロボットに対して、禁止している事項などが記載されています。下記は今回使用するみんなの株式のrobots.txtになります。
User-Agent: * Allow: / Sitemap: https://assets.minkabu.jp/concerns/sitemap/sitemap.xml.gz Sitemap: https://assets.minkabu.jp/concerns/sitemap/news/sitemap.xml.gz Sitemap: https://minkabu.jp/hikaku/sitemap.xml Sitemap: https://minkabu.jp/beginner/sitemap.xml Disallow: /user/follow/ Disallow: /user/unfollow/ Disallow: /user/add_favorite_user/ Disallow: /user/add_favorite_stock/ Disallow: /user/add_respect_user/ Disallow: /user/switch/ Disallow: /user/resign/ Disallow: /message/to/ Disallow: /blog/edit Disallow: /stocks/pick/open_form Disallow: /stock/*/community/edit Disallow: /simulation/simple/start Disallow: /community/join/ Disallow: /groups/topic/edit Disallow: /invite/group/ Disallow: /home Disallow: /top/report/ Disallow: /94446337/ Disallow: /hikaku/redirect/
上記の場合、Allowですべての公開ページを許可していますが、Disallowにはその中でもアクセスさせたくないページを記載しています。
情報取得先
上記の調査より、情報取得先を決定しました。
・日本取引所グループ
・みんなの株式
・IP BANK
・おかねまみれ
銘柄コードとスクリーニング条件に含まれる株価・配当金情報は下記より取得します。
| 取得したい情報 | 情報取得先 |
|---|---|
| 銘柄コード | 日本取引所グループ |
| 配当利回り | みんなの株式 |
| PBR | みんなの株式 |
| 配当性向 | IP BANK |
| 自己資本比率 | IP BANK |
| 売上営業利益率 | IP BANK |
| 配当実績(増配傾向) | おかねまみれ |
取得ページ・ファイル
情報を取得したページ・ファイルは下記の通りになります。
出典 : その他統計資料 | 日本取引所グループ

- みんなの株式
出典 : アサヒホールディングス (5857) : 株価チャート [Asahi Holdings] - みんなの株式 (みんかぶ)

- IP BANK

- おかねまみれ

スクリーニングツール作成
環境構築
今回はPythonを使って作成しました。pipで下記のパッケージをインストールしています。
pip install requests pip install pandas pip install lxml pip install xlrd pip install openpyxl
事前準備
ファイルの連結
IP BANK、おかねまみれから取得する情報は決算情報や配当金の情報になります。この情報を平日に毎回取得する必要はないので、事前にcsvファイルをマージしたものを作ります。
下記のコードで必要な列情報のみを読み取り、コードにより連結しました。(各csvファイルは1行目にヘッダが表示されるように事前処理しています。)
import pandas as pd stock_dividend_path = 'fy-stock-dividend.csv' profit_loss_path = 'fy-profit-and-loss.csv' blance_path = 'fy-balance-sheet.csv' dividend_record_path = '国内株配当実績取得ツール_20200513.xlsm' target_path = 'fy-merged-sheet.csv' blance_data_frame = pd.read_csv(blance_path,usecols=['コード','年度','自己資本比率']) profit_data_frame = pd.read_csv(profit_loss_path,usecols=['コード','売上高','営業利益']) stock_data_frame = pd.read_csv(stock_dividend_path,usecols=['コード','一株配当','配当性向']) dividend_record_data_frame = pd.read_excel(dividend_record_path,usecols=['コード','連続増配','減配なし']) data_list = [blance_data_frame, profit_data_frame, stock_data_frame, dividend_record_data_frame] tmp = data_list[0] for data in data_list[1:]: tmp = pd.merge(tmp,data,on='コード') tmp.to_csv(target_path,index=False,encoding='shift-jis')
連結したcsvファイルは下記の通りです。

実装
東証一部上場の銘柄のコード取得
要件として、東証一部上場の株式情報を取得するとしています。事前準備で用意したファイルには、東証一部上場以外の企業も含まれていますので、銘柄コードを取得します。
日本取引所グループのサイトからDeveloper Toolを使用して、東証上場銘柄一覧のファイルパスを取得します。

そのExcelシートから、"コード"、"銘柄名"、"市場・商品区分"、"17業種区分"を取得します。

ソースコードは下記の通りになっています。
# Obtain the code and stock information listed on the First Section of the Tokyo Stock Exchange from https://www.jpx.co.jp/. source_path = 'https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls' data_frame = pd.read_excel(source_path,usecols=['コード','銘柄名','市場・商品区分','17業種区分'],sheet_name='Sheet1') stock_data_frame = data_frame[data_frame['市場・商品区分']=='市場第一部(内国株)']
Webスクレイピング
みんなの株式の株価、配当金情報を取得します。
下記のサイトのURLは、https://minkabu.jp/stock/5857/chartのようになっています。この5857が銘柄コードになっており、他の銘柄の情報を取得する場合には銘柄のコードを変更する必要があります。

そのため、"東証一部上場のコード取得"で取得した銘柄コードを使って、URLを作ります。その後に、requestsのgetメソッドを使ってHTMLページを取得する形で実装しました。
chart_url = "https://minkabu.jp/stock/" + str(stock_code) + "/chart" try: chart_html = requests.get(chart_url)
取得する株の情報は、下記の形でXPathで参照しています。
# 配当利回り stock_dividend_yield = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[3]/td[1]','%','')
XPathはDeveloper Toolで取得することができます。

スクリーニング
配当利回りと配当実績(増配傾向)は、優先度が高いので、それらが空になっているものはExcelデータに出力しないようにしています。
スクリーニングの定義と条件は下記のように実装しました。
# スクリーニングの定義 ENABLE_DIVIDEND_YIELD = True TARGET_DIVIDEND_YIELD = 3.75 ... # スクリーニングの条件 def util_screening(dividend_yield,dividend_payout_ratio,pbr,capital_adequacy_ratio,operating_profit_ratio,continuous_dividend_increase): if ENABLE_DIVIDEND_YIELD: # Dividend_yield has a high priority and does not allow None. if dividend_yield is not None and dividend_yield >= TARGET_DIVIDEND_YIELD: pass else: return False ...
スクリーニング結果
"市場第一部(内国株)"の2191件の中から3件の株式情報が取得できました。配当利回りの高い銘柄から順に確認するため、配当利回りでソートするようにしています。

※上記のキャプチャでは一部の情報のみ表示しています。実際には、下記の情報が表示されます。
columns = ['コード',\ '銘柄',\ '前日終値',\ '高値',\ '安値',\ '年初来高値',\ '年初来安値',\ 'PER(倍)',\ 'PBR(倍)',\ '配当利回り(%)',\ '年度',\ '売上高',\ '営業利益',\ '営業利益率',\ '自己資本率',\ '一株配当',\ '配当性向(%)',\ '連続増配',\ '減配なし',\ '業種']
ソースコード
ソースコードは下記のようになります。
import requests import pandas as pd import lxml.html import sys import time from time import strftime SCREENING = True ENABLE_DIVIDEND_YIELD = True TARGET_DIVIDEND_YIELD = 3.75 ENABLE_PAYOUT_RATIO = True TARGET_PAYOUT_RATIO = 50 ENABLE_PBR = True TARGET_PBR = 1.5 ENABLE_CAPTIAL_ADEQUACY_RATIO = True TARGET_CAPTIAL_ADEQUACY_RATIO = 50 ENABLE_OPERATING_PROFIT_RATIO = True TARGET_OPERATING_PROFIT_RATIO = 10 ENABLE_CONTINUOUS_DIVIDEND_INCREASE = True TARGET_CONTINUOUS_DIVIDEND_INCREASE = 3 """ # Purpose Convert source variable contained in str variable to destination variable. """ def util_replace(text, source, destination): # if text has source if text.find(source) > 0: # remove unnecessary ',' tmp = text.replace(',','') return float(tmp.replace(source, destination)) else: # Replace non-valued data with None. return None """ # Purpose Confirm that it matches the following conditions. """ def util_screening(dividend_yield,dividend_payout_ratio,pbr,capital_adequacy_ratio,operating_profit_ratio,continuous_dividend_increase): if ENABLE_DIVIDEND_YIELD: # Dividend_yield has a high priority and does not allow None. if dividend_yield is not None and dividend_yield >= TARGET_DIVIDEND_YIELD: pass else: return False if ENABLE_PAYOUT_RATIO: # Since dividend_payout_ratio has a low priority, allow None. if dividend_payout_ratio is None or dividend_payout_ratio <= TARGET_PAYOUT_RATIO: pass else: return False if ENABLE_PBR: # Since pbr has a low priority, allow None. if pbr is None or pbr <= TARGET_PBR: pass else: return False if ENABLE_CAPTIAL_ADEQUACY_RATIO: if capital_adequacy_ratio is None or capital_adequacy_ratio >= TARGET_CAPTIAL_ADEQUACY_RATIO: pass else: return False if ENABLE_OPERATING_PROFIT_RATIO: # Since operating_profit_ratio has a low priority, allow None. if operating_profit_ratio is None or operating_profit_ratio >= TARGET_OPERATING_PROFIT_RATIO: pass else: return False if ENABLE_CONTINUOUS_DIVIDEND_INCREASE: # Since continuous_dividend_increase has a high priority, does not allow None. if continuous_dividend_increase is not None and continuous_dividend_increase >= TARGET_CONTINUOUS_DIVIDEND_INCREASE: pass else: return False return True """ # Purpose Parse dom_tree and get text data. """ def parse_dom_tree(dom_tree, xpath, source, destination): raw_data = dom_tree.xpath(xpath) data = util_replace(raw_data[0].text,source,destination) return data """ # Purpose Confirm that the string can be converted to float type. """ def isfloat(text): try: float(text) except ValueError: return False else: return True """ # Purpose Convert string type to float type. """ def convert_string_float(text): if isfloat(text): return float(text) else: return None if __name__ == '__main__': # Obtain the code and stock information listed on the First Section of the Tokyo Stock Exchange from https://www.jpx.co.jp/. source_path = 'https://www.jpx.co.jp/markets/statistics-equities/misc/tvdivq0000001vg2-att/data_j.xls' data_frame = pd.read_excel(source_path,usecols=['コード','銘柄名','市場・商品区分','17業種区分'],sheet_name='Sheet1') stock_data_frame = data_frame[data_frame['市場・商品区分']=='市場第一部(内国株)'] merged_data_path = 'fy-merged-sheet.csv' merged_data_frame = pd.read_csv(merged_data_path,encoding='shift-jis',usecols=['コード','年度','自己資本比率','売上高','営業利益','一株配当','配当性向','連続増配','減配なし']) stock_merged_data_frame = merged_data_frame.set_index('コード') output_list = [] for index,row in stock_data_frame.iterrows(): stock_code = row[0] stock_name = str(row[1]) stock_industry_type = str(row[3]) if stock_code in stock_merged_data_frame.index: merged_data_list = stock_merged_data_frame.loc[int(stock_code)] else: continue chart_url = "https://minkabu.jp/stock/" + str(stock_code) + "/chart" try: chart_html = requests.get(chart_url) chart_html.raise_for_status() chart_dom_tree = lxml.html.fromstring(chart_html.content) print(stock_code) # 前日終値 stock_previous_closing_place = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[1]//tr[1]/td[1]','円','') #print('stock_previous_closing_place : ' + str(stock_previous_closing_place)) # 高値 stock_high_place = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[1]//tr[3]/td[1]','円','') #print('stock_high_place : ' + str(stock_high_place)) # 安値 stock_low_place = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[1]//tr[4]/td[1]','円','') #print('stock_low_place : ' + str(stock_low_place)) # PER stock_per = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[1]/td[1]','倍','') #print('stock_per : ' + str(stock_per)) # PBR stock_pbr = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[2]/td[1]','倍','') #print('stock_pbr : ' + str(stock_pbr)) # 年初来高値 stock_high_place_per_year = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[6]/td[1]','円','') #print('stock_high_place_per_year : ' + str(stock_high_place_per_year)) # 年初来安値 stock_low_place_per_year = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[7]/td[1]','円','') #print('stock_low_place_per_year : ' + str(stock_low_place_per_year)) # 配当利回り stock_dividend_yield = parse_dom_tree(chart_dom_tree,'//*[@id="contents"]/div[3]/div[1]/div/div/div[2]/div/div[2]//tr[3]/td[1]','%','') #print('stock_dividend_yield : ' + str(stock_dividend_yield)) # 年度 stock_term = merged_data_list['年度'] # 自己資本比率 stock_capital_adequacy_ratio = merged_data_list['自己資本比率'] # 売上高営業利益率 営業利益 / 売上高 stock_operating_profit = convert_string_float(merged_data_list['営業利益']) stock_sales = convert_string_float(merged_data_list['売上高']) if stock_operating_profit is None or stock_sales is None: stock_operating_profit_ratio = None else: stock_operating_profit_ratio = (stock_operating_profit / stock_sales) * 100 # 一株配当 stock_dividend_per_share = convert_string_float(merged_data_list['一株配当']) # 配当性向 stock_dividend_payout_ratio = convert_string_float(merged_data_list['配当性向']) # 連続増配 stock_continuous_dividend_increase = merged_data_list['連続増配'] # 減配なし stock_dividend_reduction = merged_data_list['減配なし'] if(SCREENING == True): if(util_screening(stock_dividend_yield,stock_dividend_payout_ratio,\ stock_pbr,stock_capital_adequacy_ratio,\ stock_operating_profit_ratio,stock_continuous_dividend_increase)): list = [stock_code,\ stock_name,\ stock_previous_closing_place,\ stock_high_place,\ stock_low_place,\ stock_high_place_per_year,\ stock_low_place_per_year,\ stock_per,\ stock_pbr,\ stock_dividend_yield,\ stock_term,\ stock_sales,\ stock_operating_profit,\ stock_operating_profit_ratio,\ stock_capital_adequacy_ratio,\ stock_dividend_per_share,\ stock_dividend_payout_ratio,\ stock_continuous_dividend_increase,\ stock_dividend_reduction,\ stock_industry_type] else: continue else: list = [stock_code,\ stock_name,\ stock_previous_closing_place,\ stock_high_place,\ stock_low_place,\ stock_high_place_per_year,\ stock_low_place_per_year,\ stock_per,\ stock_pbr,\ stock_dividend_yield,\ stock_term,\ stock_sales,\ stock_operating_profit,\ stock_operating_profit_ratio,\ stock_capital_adequacy_ratio,\ stock_dividend_per_share,\ stock_dividend_payout_ratio,\ stock_continuous_dividend_increase,\ stock_dividend_reduction,\ stock_industry_type] output_list.append(list) except requests.exceptions.RequestException as e: print(e) columns = ['コード',\ '銘柄',\ '前日終値(円)',\ '高値(円)',\ '安値(円)',\ '年初来高値(円)',\ '年初来安値(円)',\ 'PER(倍)',\ 'PBR(倍)',\ '配当利回り(%)',\ '年度',\ '売上高',\ '営業利益',\ '売上高営業利益率',\ '自己資本率',\ '一株配当',\ '配当性向(%)',\ '連続増配',\ '減配なし',\ '業種'] output_data_frame = pd.DataFrame(data=output_list,columns=columns) sorted_output_data_frame = output_data_frame.sort_values('配当利回り(%)',ascending=False) localtime = strftime("%y%m%d_%H%M%S",time.localtime()) output_file_name = './stock_' + localtime + '.xlsx' sorted_output_data_frame.to_excel(output_file_name,index=None,engine='openpyxl')
まとめ
Webスクレイピングを行って、高配当株の管理に使用するスクリーニングツールを作成しました。要件2を満たすものは出来たので、続きとして要件1を満たすように実装したいと思います。
リクエストがありましたら、ネット上にスクリーニングをかける前・かけた後のファイルを掲載することなども検討しますので、気軽にコメントをいただければと思います。
続編を追記しましたので、こちらもご覧になってください。
cojimaru-chan.hatenablog.com
初心者に分かるようにIFTTTの始め方を説明してみた
最近では、Twitter,インスタグラム、LINE、Drop Boxなど、多くの便利なサービスが世の中に出回っています。 あるサービスとあるサービスを連携させることで、例えば、駅に着いたら、お父さんに迎えの連絡を入れたり、離れた場所からスマートフォンのボタンを押すだけでお風呂にお湯を入れたりできたら便利ですよね。
今回は、そのようなサービスとサービスを連携することができるサービス IFTTTについて説明します。
IFTTTの概要
IFTTTとは
IFTTT(イフト : IF This Then That)とは、異なるサービス同士を連携することができるWebサービスです。『もしあるサービスで〇〇したら、あるサービスで××する』という意味で使われています。
例えば、下記のように使うことができます。
IFTTTで使用される重要な用語として、3つあります。
- トリガー : IFTTTのIf Thisにあたる部分で、別のサービスが稼働するきっかけを作ります。
- アクション : IFTTTのThen Thatにあたる部分で、あるサービスのきっかけがなければ動作しません。きっかけにより、別のサービスが動作します。
- アプレット : IFTTTのIf This Then That全体にあたります。
料金
IFTTTは、2020年10月から有料になっており、無料の場合には3つのアプレットしか作成できません。有料の場合には、無制限のアプレットが利用できます。
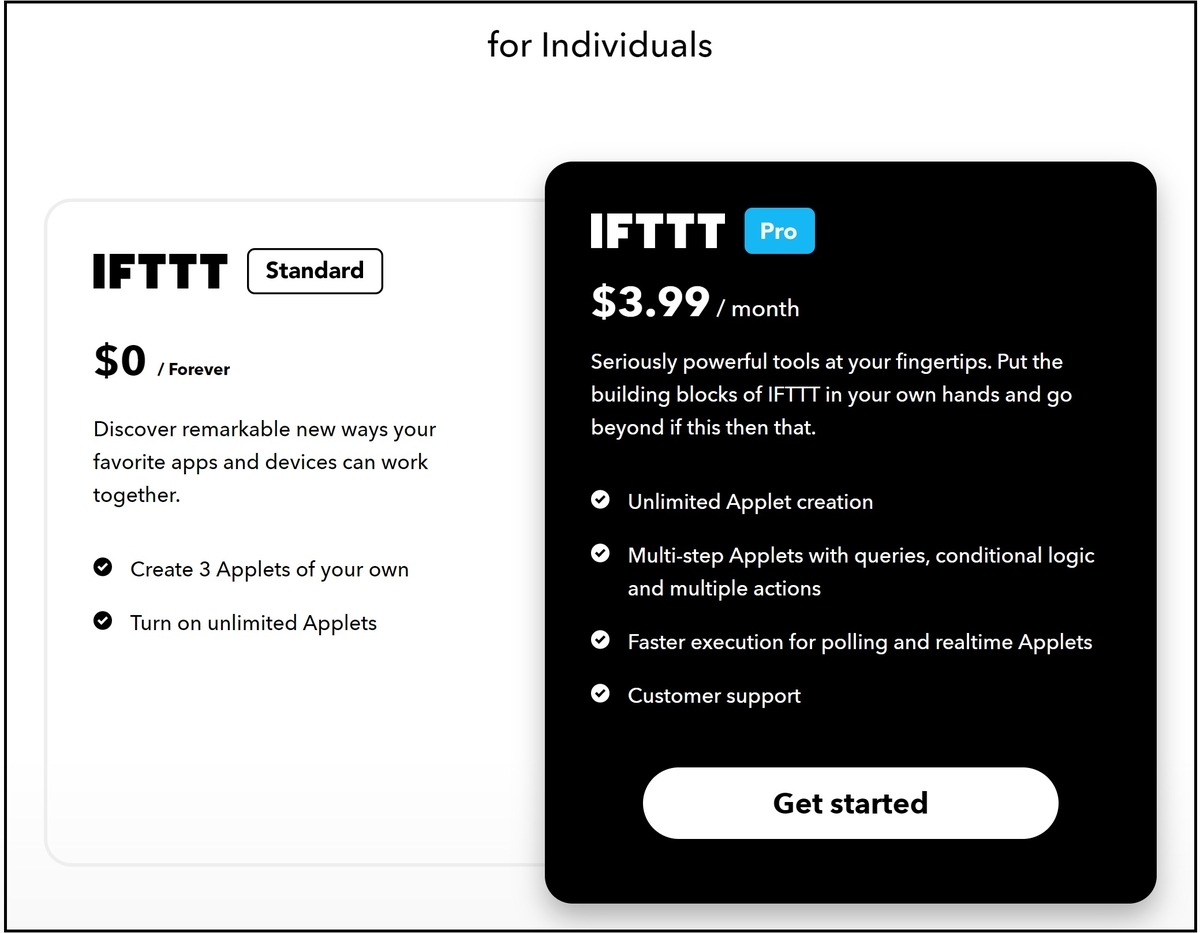
同じようなアプリとして、ZapierやMicrosoft Power Automateなどがあります。筆者としては、下記の理由により別アプリを活用することを選びませんでした。
IFTTTを使ってみた
アカウント登録
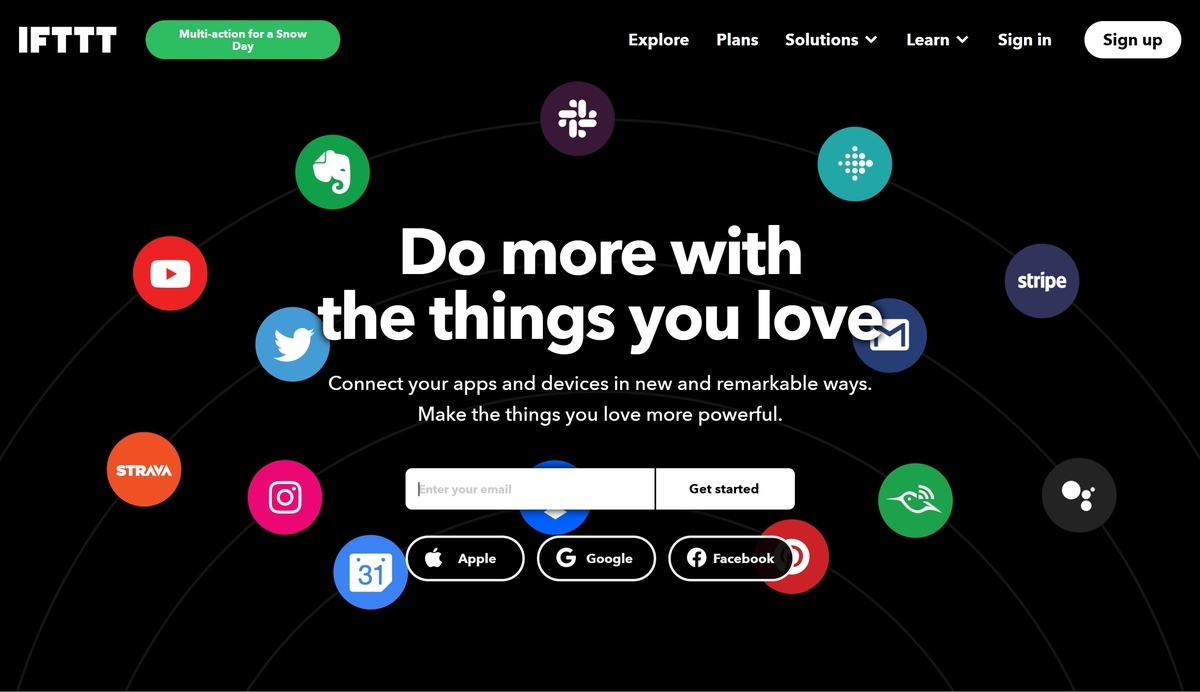
まず、IFTTTのサービスを使うために、アカウント登録を行います。ブラウザでIFTTT helps every thing work better togetherにアクセスします。画面右上のSign upを押下します。
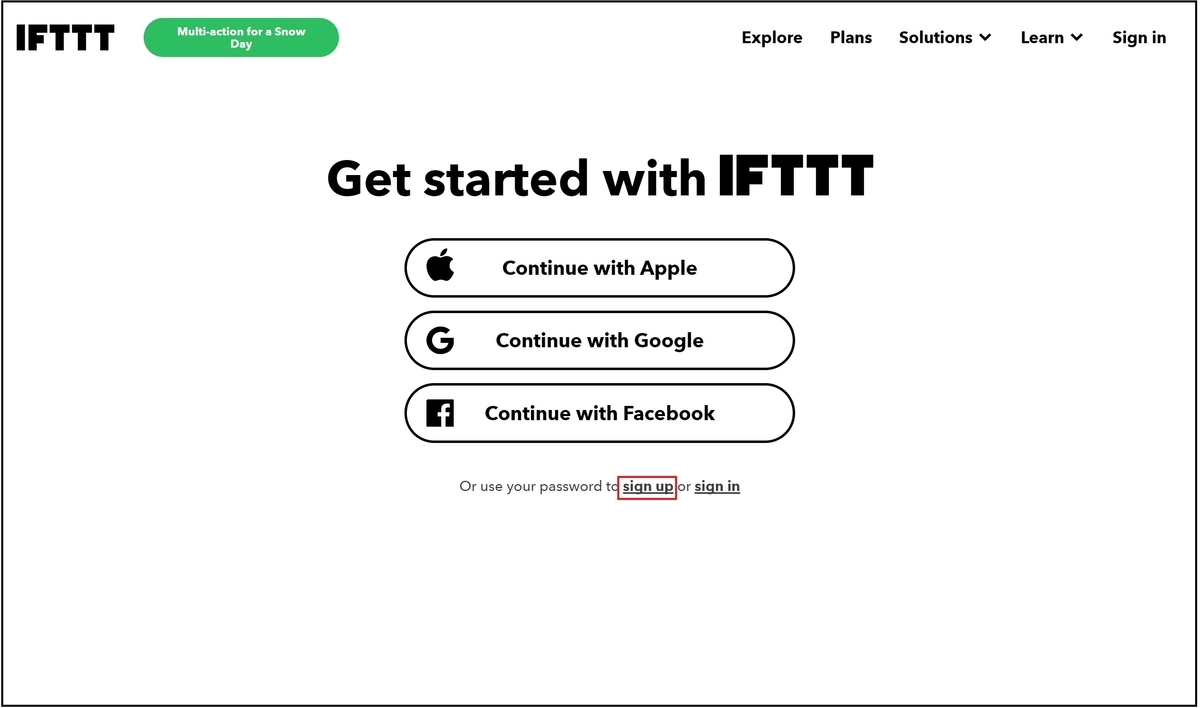
今回はメールアドレスとパスワードでアカウントを登録したいので、下記のsign upを押下します。
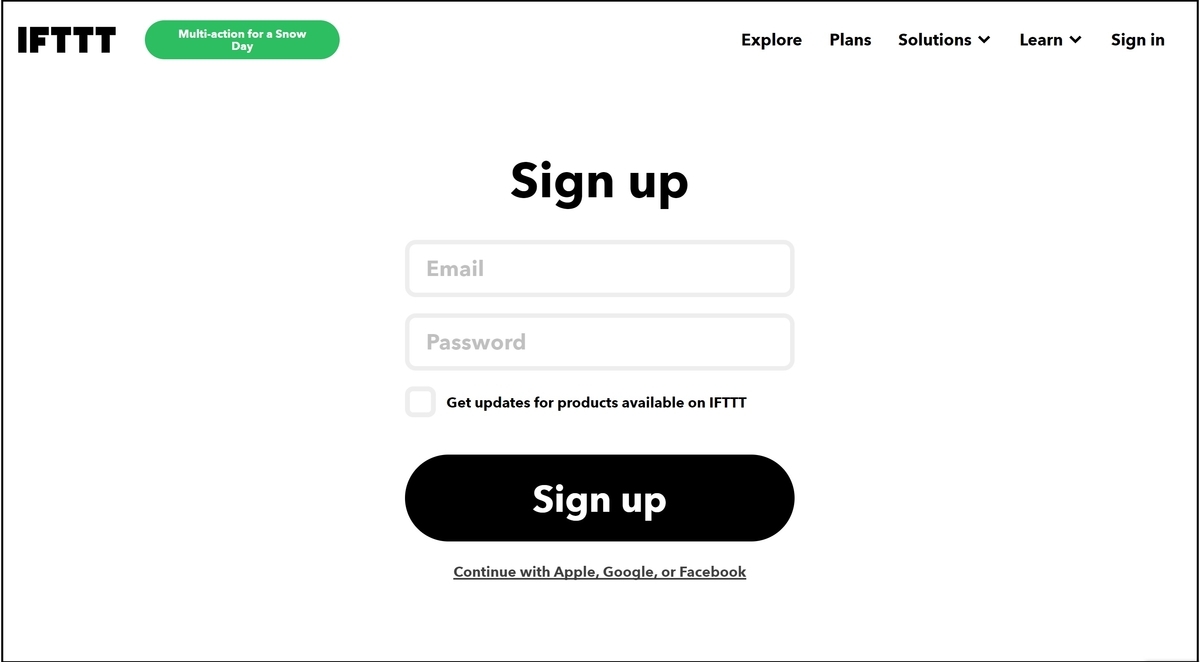
メールアドレスとパスワードを入力し、Sign upを押下します。
アカウントの登録ができました。
アプレット作成
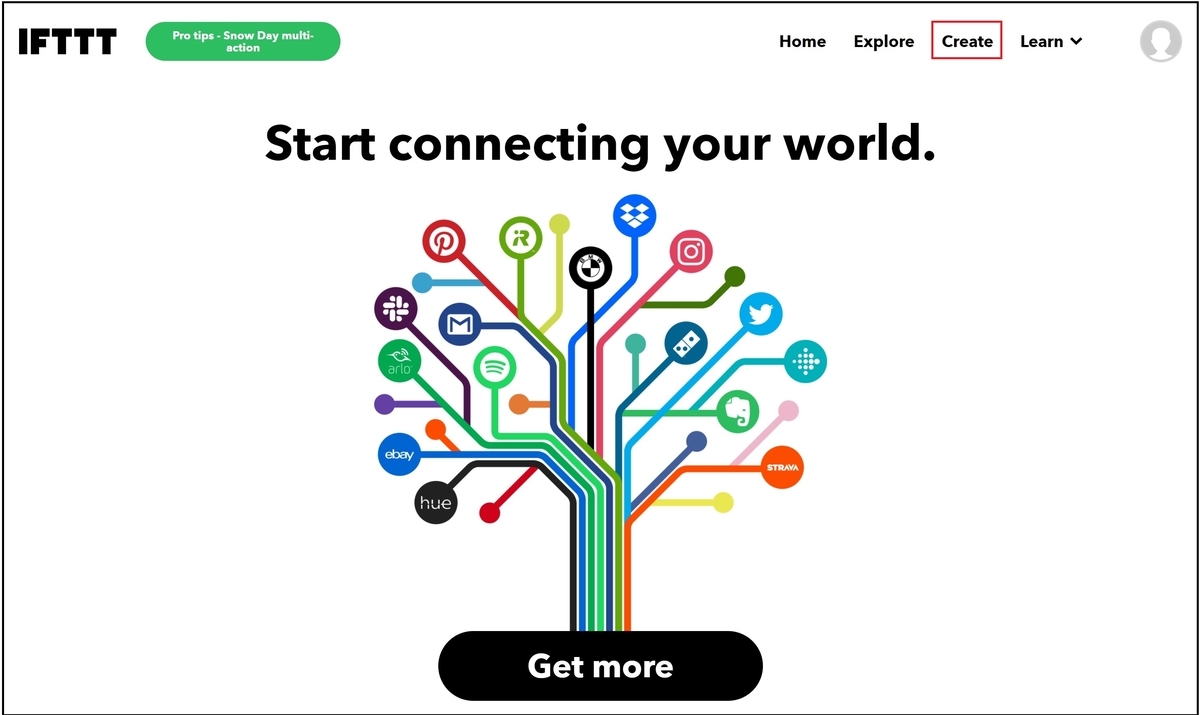
次に、アプレットの作成に移ります。今回はスマートフォン(iphone)に『新しい写真が追加された時』に、『クラウド上のドライブ(OneDrive)に写真を保存する』アプレットの作成を行います。画面右上のCreateを押下します。
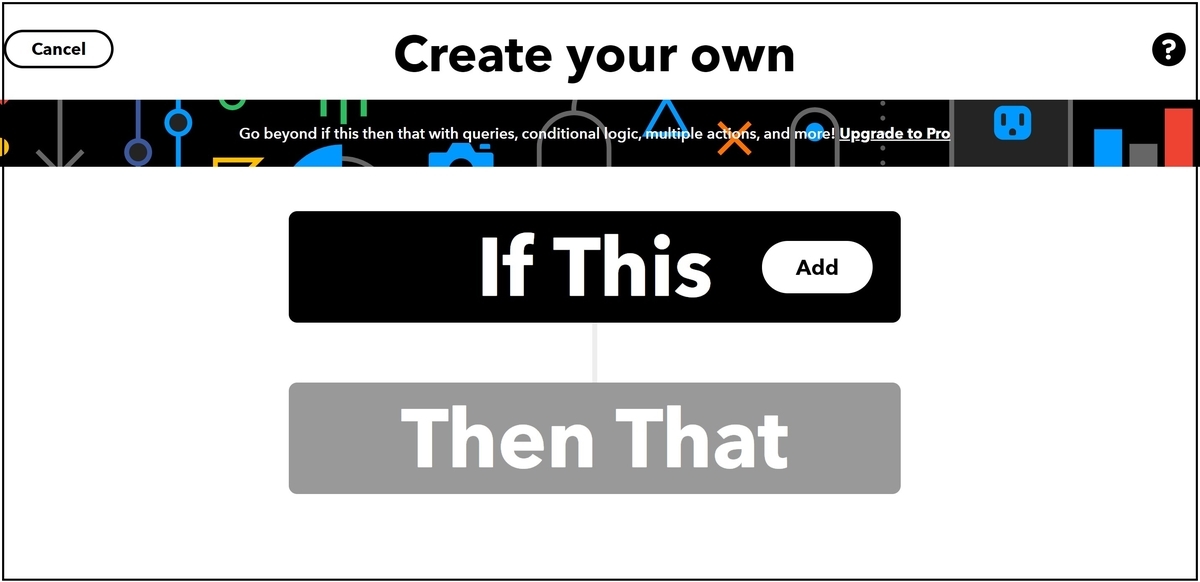
まず、If Thisをクリックします。
Thisとして登録できるサービスが表示されます。
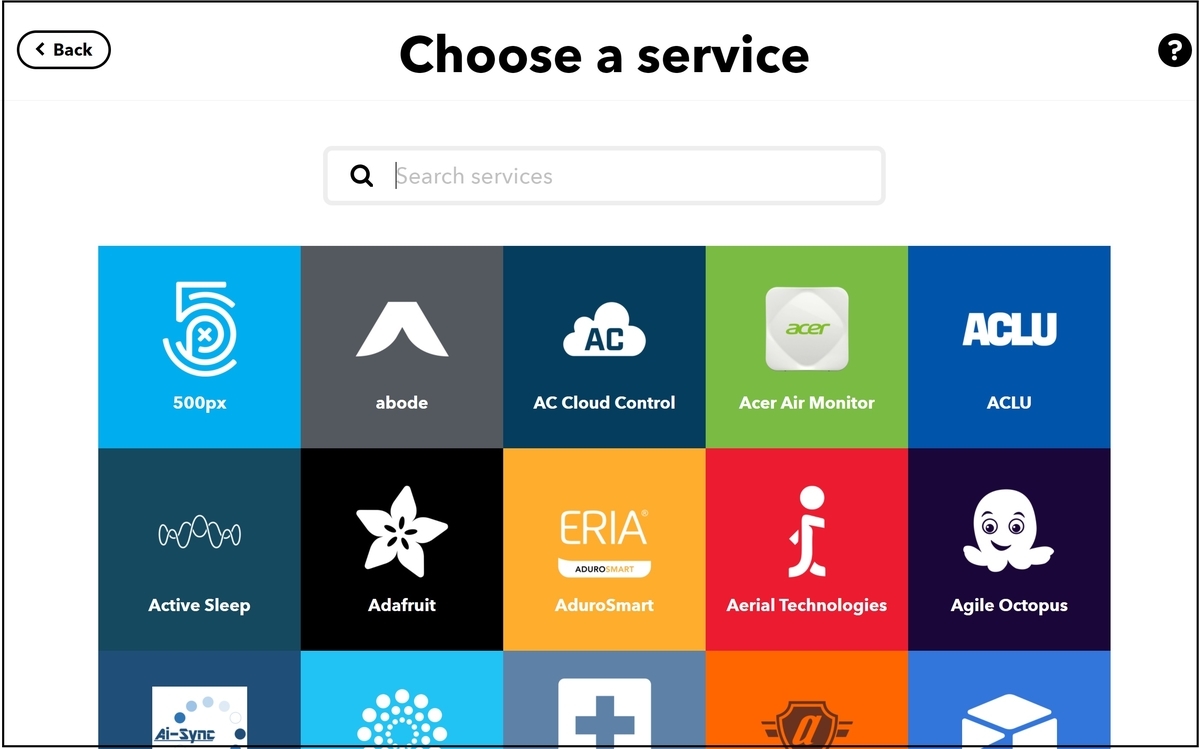
photoで検索し、iOS Photosを選択します。
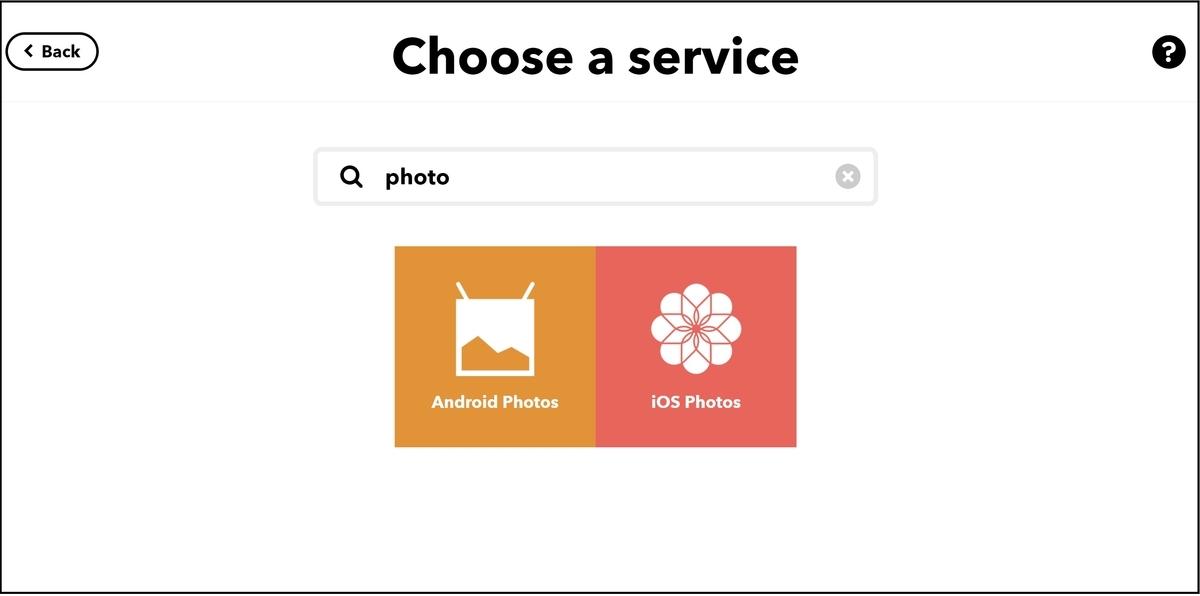
トリガーを選択できます。『新しい写真が追加された場合』なので、Any new photoを選択します。
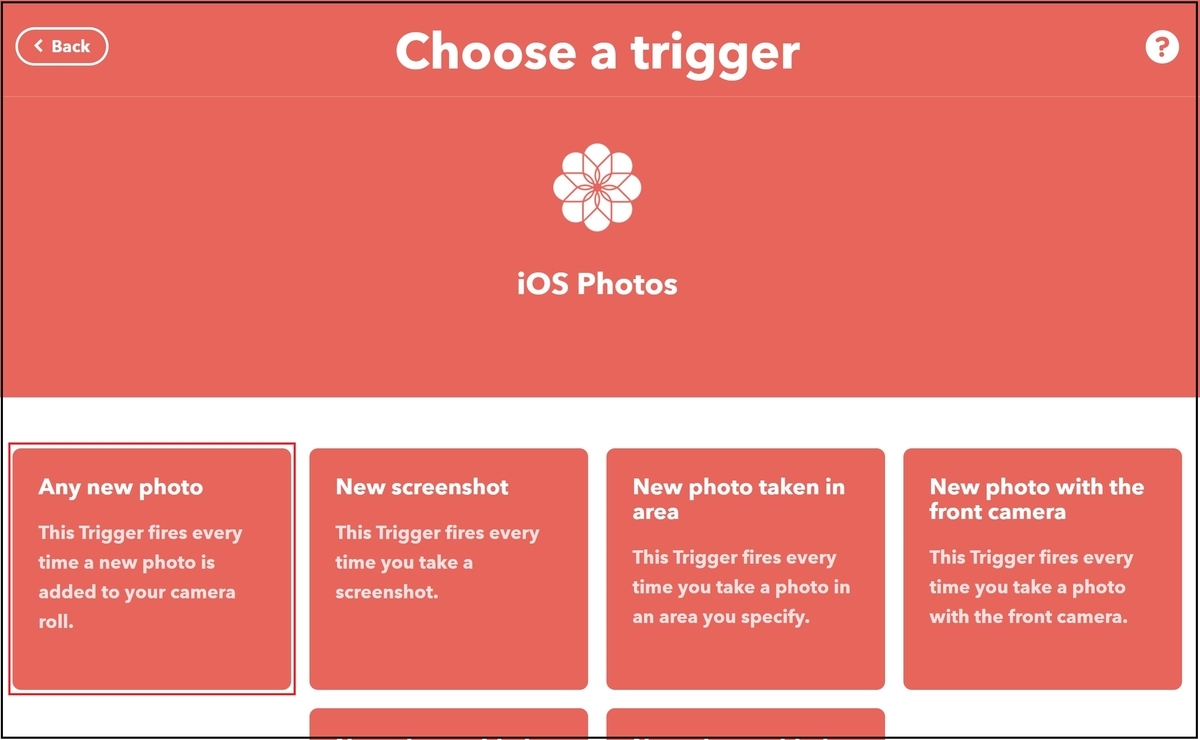
Connectを押下します。

Thisの登録が完了しました。次は、Then Thatを押下します。
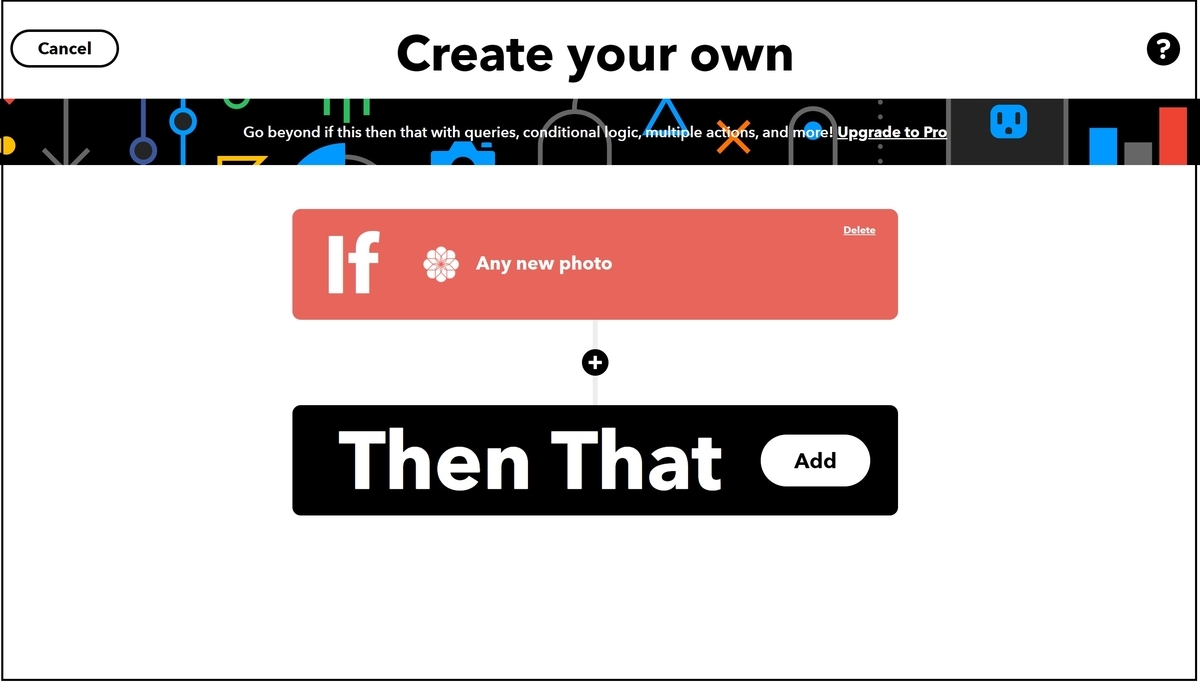
onedriveで検索し、OneDriveを選択します。
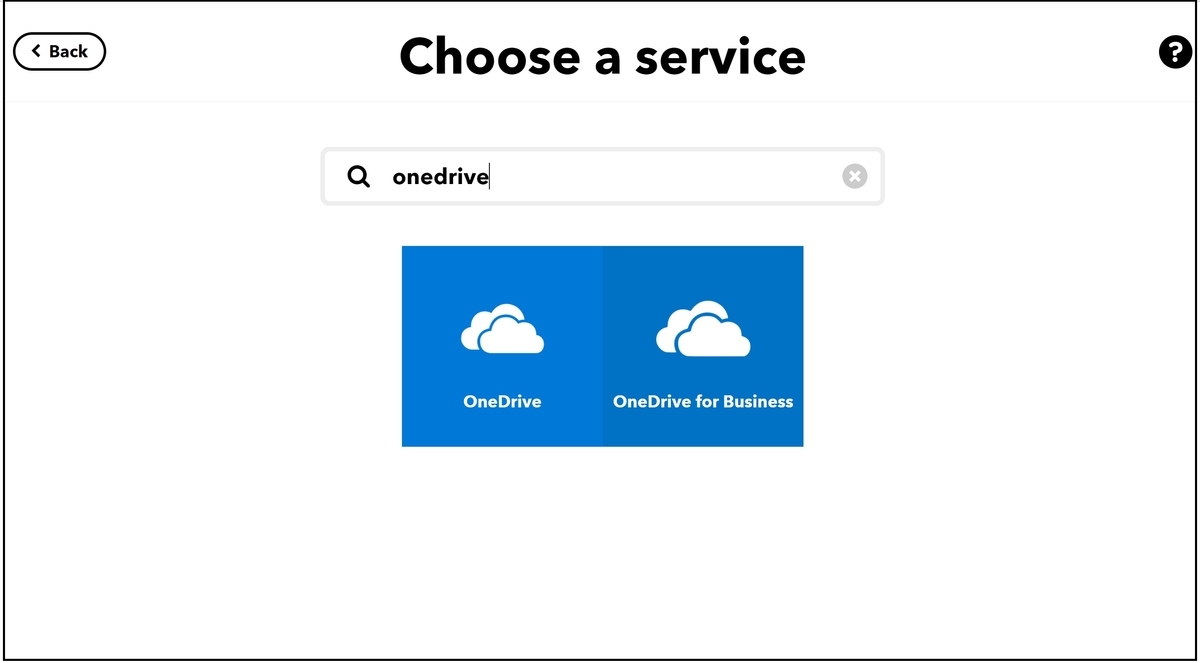
今回は写真を『OneDriveに保存したい』ため、Add file from URLを選択します。
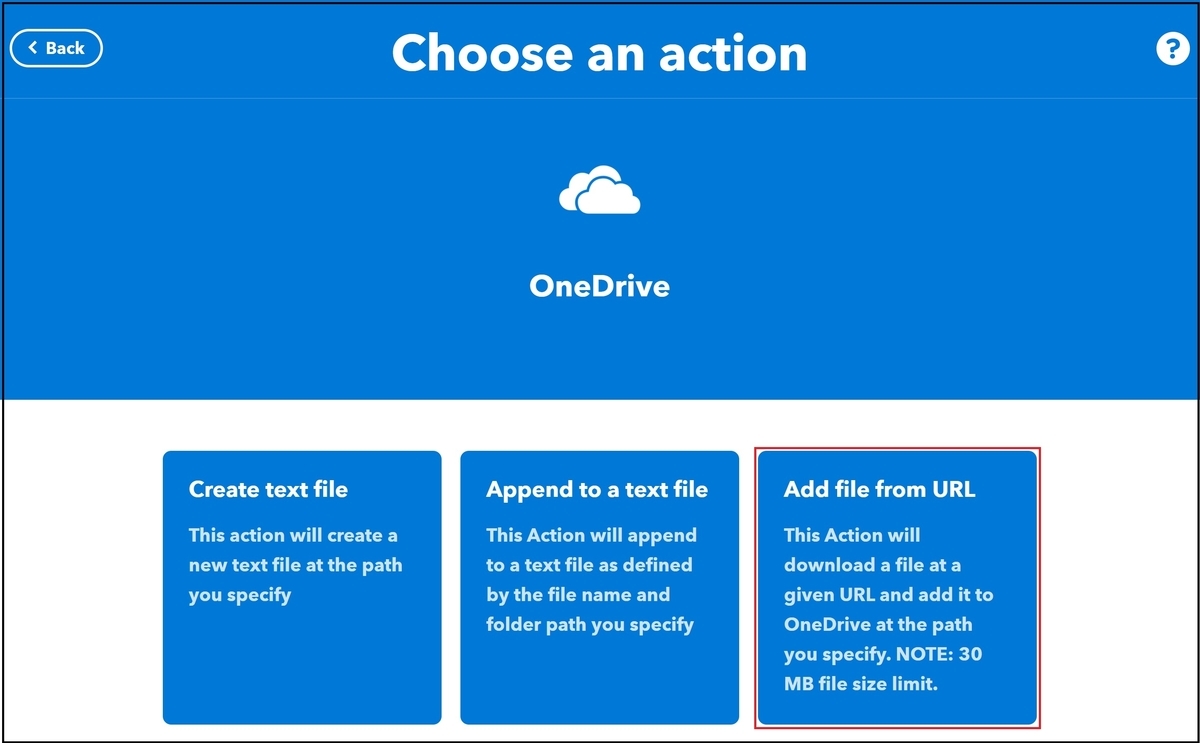
Connectを押下します。
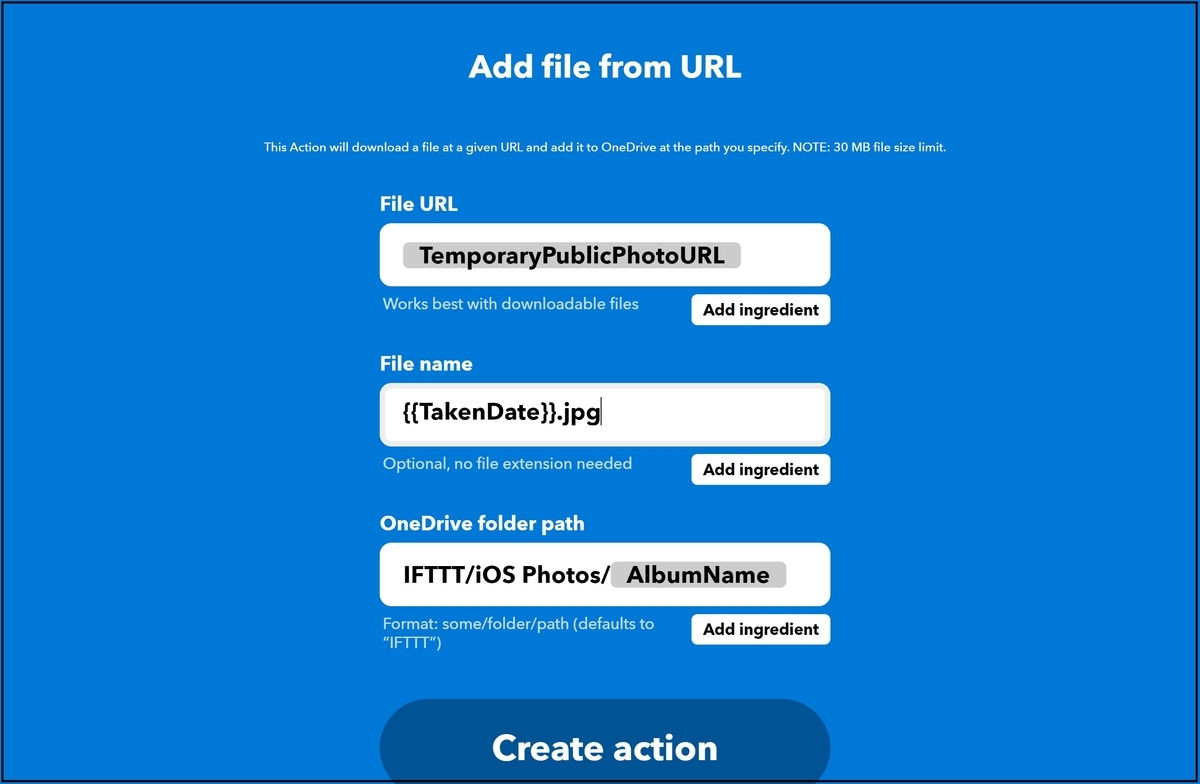
登録先のフォルダ、ファイル名などの情報を入力できます。デフォルトで値が入力されていましたが、File Nameのみjpgの拡張子を追加しました。入力が完了しましたら、Create actionを押下します。
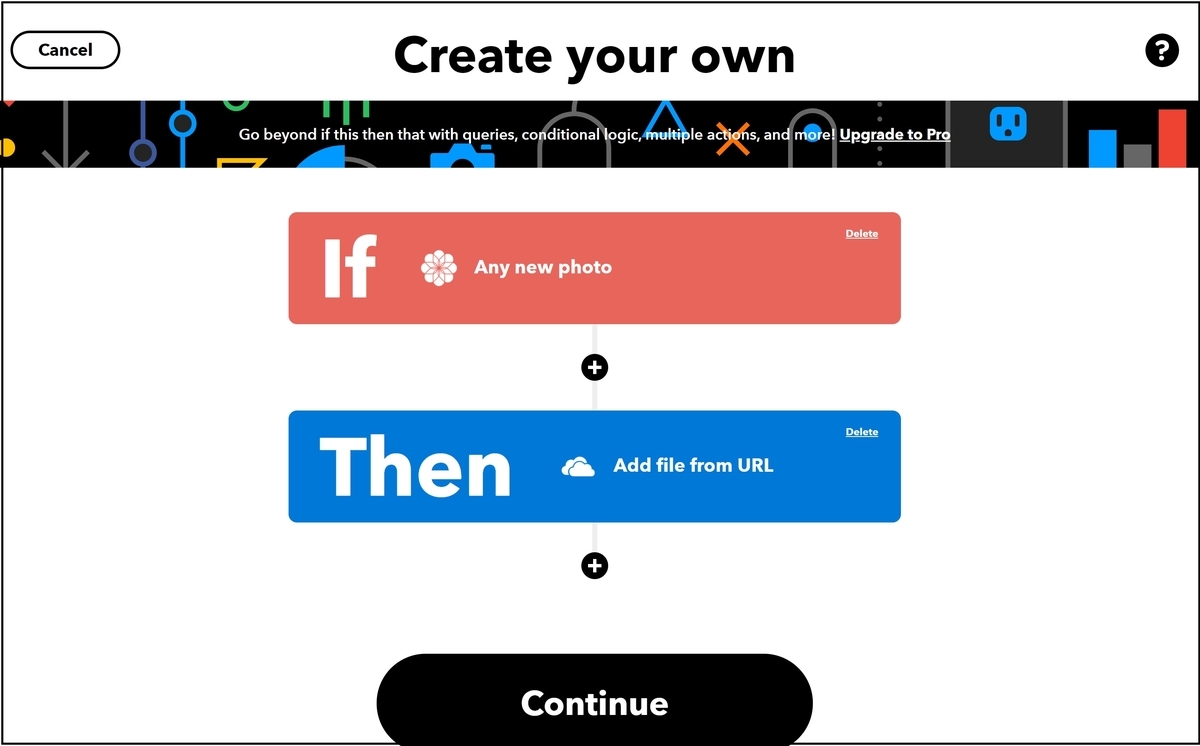
ThisとThatが登録できました。Continueを押下します。
最後に、アプレットのタイトルを入力します。完了しましたら、Finishを押下します。
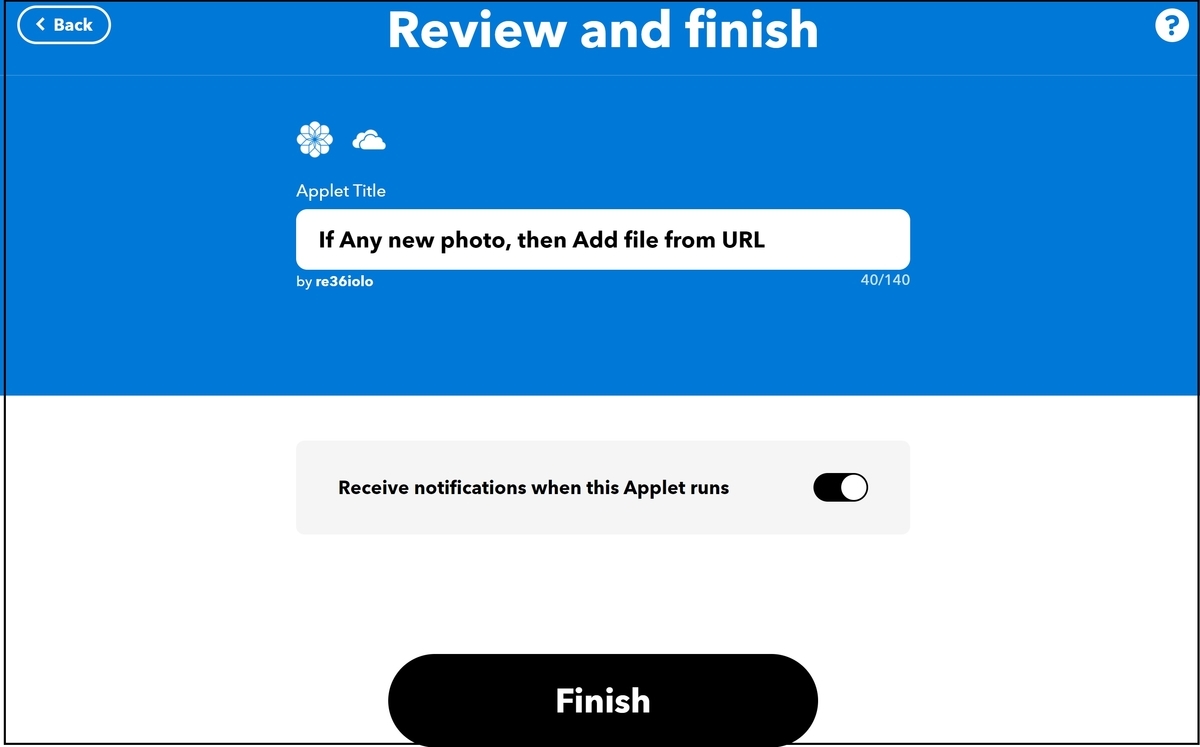
これで、アプレットの登録は完了しました。
このアプレットはスマホのアプリで動作させる必要があります。そのため、スマホにもIFTTTのアプリをダウンロードしました。

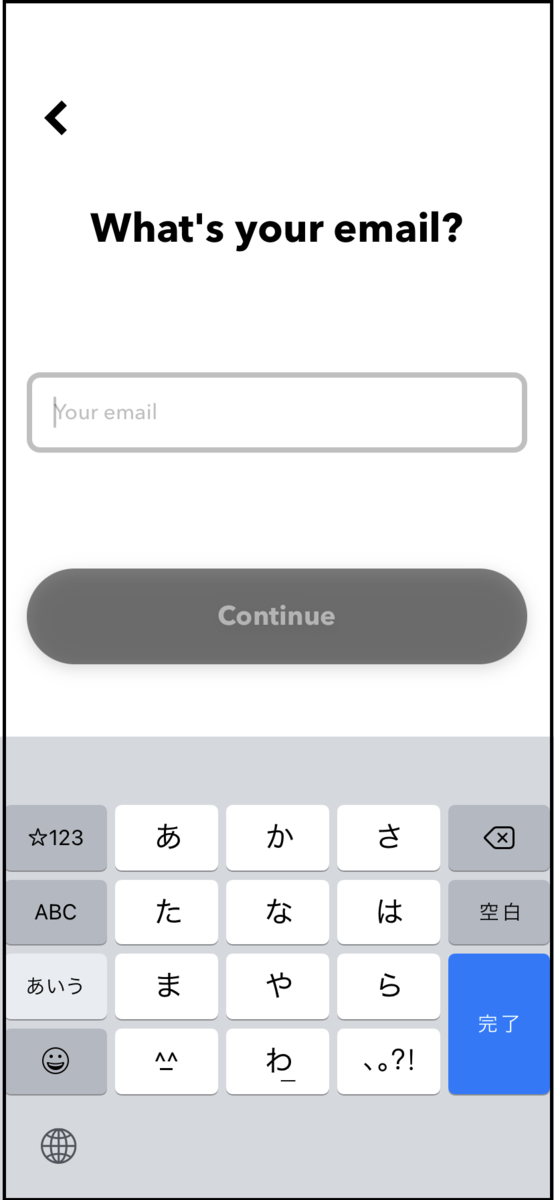
先ほど、アカウントをemailで登録したため、Continue with Emailを選択します。

先ほど登録したemailを入力します。完了しましたら、Continueを押下します。続いてパスワードの入力を求められるので、そちらも入力します。
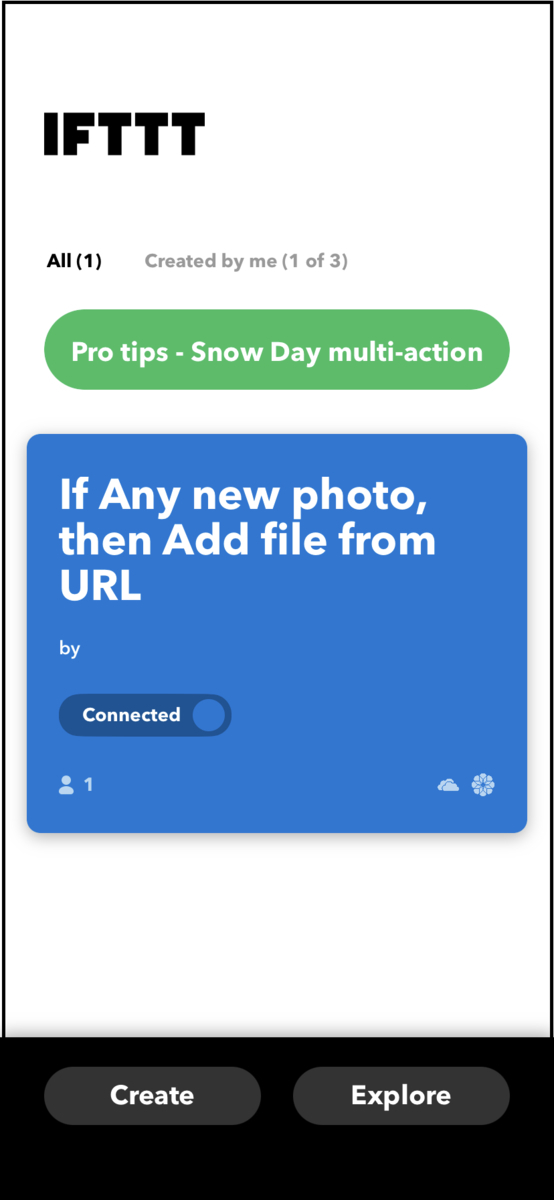
先ほど登録したアプリが確認できました。
動作確認
アプレットが正しく動作することを確認するために、
- スマートフォンで写真を撮った場合に、OneDriveに写真が保存されること
- IFTTTのログにその情報が保存されること
を確認します。
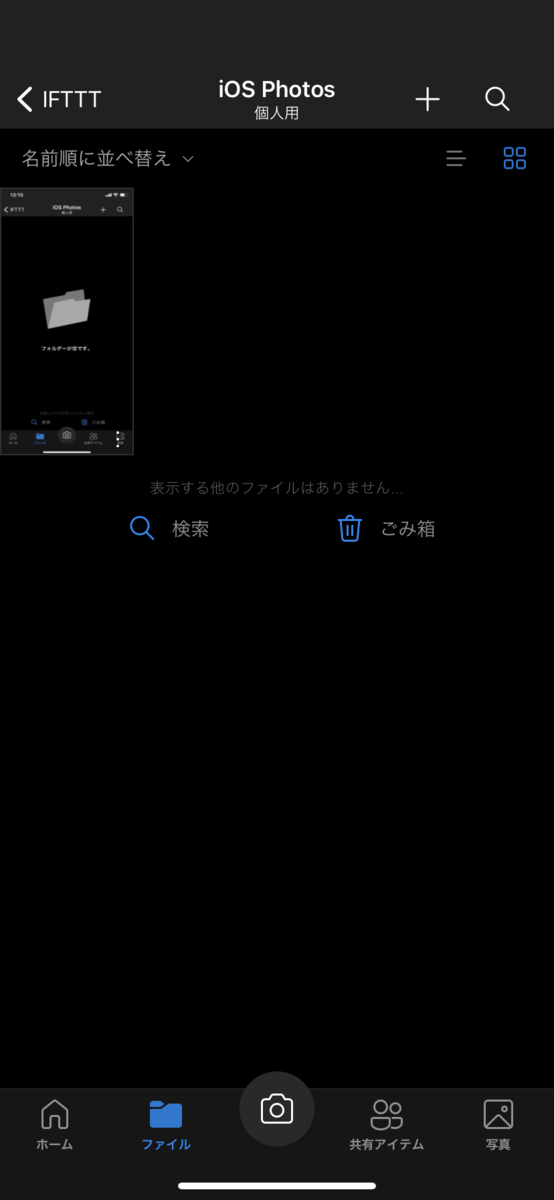
まず、OneDriveの写真の保存先に含まれるデータを空にし、そのスクリーンショットを撮ります。

数秒時間が経過した後に、OneDriveを確認すると下記の通り写真が保存されていました。
次に、IFTTTよりログを確認します。先ほどのIFTTTの画面より、アプレットを選択します。
画面右上の歯車マークを押下します。

下記のView activity logを押下します。IFTTTが動作したことの通知を受け取りたい場合は、Receive notifications when this Applet is activeのスイッチをオンにします。

ログを確認すると、下記の通り、アプレットが動作していました。

感想
ブログで使用する写真を撮るのにスマホを使っていますが、IFTTTを使うことにより自動でOneDriveにアップロードしてくれるようになるのですごく便利ですね。将来的には、スマートスピーカーやIoTボタンなどと連携させて、今まで余計に時間がかかっていた作業などを無くしていきたいです。
パナソニック食洗機 NP-TZ200購入 自分で設置してみた
どうも、こじまるです。
今回はパナソニック食洗機 NP-TZ200を購入しました。食洗器の工事まで委託すると工賃がかなり高いため、筆者が食洗器の設置工事を行いました。本記事では、その手順や方法について説明したいと思います。
食洗器の取り付け方
Panasonicが公式で出している記事の通り、蛇口に分岐水栓を取り付ける作業を行うだけで、作業が完了します。ただ、私のような素人がやりますと、簡単に済む話ではないのでご注意をください。
設置工事
一度目の挑戦
筆者は考えるよりも先に行動するのが好きなタイプです。食洗器が届いてすぐさま取り付け工事をやってみました。他の方の記事を参考に下記の工具を用意しました。
参考までに筆者が使用した工具のリンクを記載します。ドライバーは以前から筆者の家にあったものを使用しました。
BESTU 六角棒レンチ セット ボールポイント L型レンチ 六角棒レンチセット1.5/2/2.5/3/4/5/6/8/10mm ロング 精密 レンチセット 9本組
まず、蛇口から水が漏れるのを防ぐために、水・お湯の元栓を閉めます。

次に、水栓のレバーを取り外すために、写真のように温度マークの部品にマイナスドライバーを差し込み、部品を外します。

その部品を外すと、六角レンチのねじ穴があります。それを六角レンチで緩めるとレバーを取り外すことができます。
分岐水栓を取りつけるには、下記図の蛇口の上に付いている水栓を外す必要があります。他の方のブログを見ているとモーターレンチで蛇口の上側の水栓を回すことで簡単に外れると書いていたので、やってみたところ蛇口の上、下の水栓が一緒に回ってしまって、空回りしてしまいました。

結果的に、水道管がねじれてしまいました。

二度目の挑戦
一度目の挑戦後、水栓の回し方だけではなく、水道管の戻し方も調べる羽目になりました。汎用的に使えるウォーターポンププライヤーで蛇口の下の水栓を固定するといいと他の方の記事に書いていたので、購入して試してみました。
TTC ウォーターポンプぷらイヤーバネ付 300mm WP-300SC-S
結果として、蛇口の下の水栓は固定できず、空回りしてしまいました。ただ、蛇口の下の水栓はモーターレンチで回した方向と反対回しに回転させることで元に戻りました。一度目の挑戦の時はテンパっていて気づきませんでしたが、当たり前のことですよね。
三度目の挑戦
汎用的な工具で出来なかったため、最終的には専用の工具 TOTO ワンホール水栓取り外し用締付工具 TZ36を購入しました。
下記の穴に工具を入れて、固定する形で使用します。

この工具を使っても空回りしましたが、根気よく何度も挑戦した結果外すことができました。

後は、蛇口の上に分岐水栓を取り付け、その上にレバーを取り付けました。分岐水栓の取り付け作業は外す作業と比べて、ほとんど時間はかかりませんでした。

最終的に必要になった工具
結果
取り付け工事が完了するまでに、調査するのに苦労しましたが、何とか完了しました。水栓のことや工具についても勉強になったので、自分で設置して良かったと思います。

感想・まとめ
食洗器を自分で設置してみましたが、予想していた以上に苦労しました。(作業時間: 計12Hほど) 個人的には、何か問題が発生した時に対処しきれなくなる可能性もあるので、業者に依頼することをおすすめします。
LPIC 合格のための学習方法
どうも、こじまるです。
2020年12月にLPIC level2を合格しました。今後、LPICを受験される方の参考のために、私の学習方法を共有したいと思います。

対象読者
・これからLPICの受験を考えている人
・LPICに必ず合格したいと考えている人
学習期間
下記はLevel2の取得までにかかったスケジュールになります。私は試験の学習開始から試験実施まで1か月~1か月半くらいかかりました。Ping-tの掲示板を見ると2週間で受かったなどと書いていたりしますが、受験費用も高いので確実に合格を目指しました。

学習方法
筆者は下記のように学習を進めました。
①Ping-t 最強Web問題集で学習する
- 最強Web問題集の解説を読む
- 必要な情報をノートにまとめる
- 最強Web問題集の問題を解く
②Ping-t コマ問で問題を解く
③スピードマスター問題集を解く
具体的に説明していきます。
①Ping-t 最強Web問題集で学習する
基礎知識の学習のために、Ping-t 最強Web問題集の解説を活用します。Ping-t 最強Web問題集の解説は試験の読解に必要な情報がまとまっています。なので、それを十分に活用することが合格のための近道です。
1.最強Web問題集の解説を読む
Ping-t 最強Web問題集のパート毎に進めていきます。解説を使って学習するために、すべての問題を選択し、間違えてしまいましょう。上記の作業が終われば、解説を読み進めてください。

2.必要な情報をノートにまとめる
解説に書かれている内容を読むだけでは、Linuxのコマンドや内容を理解出来ません。なので、可能であれば実環境で操作をしたり、ノートに内容をまとめました。
※202は試験範囲に、Open LDAP、Samba、Web Severなどのサーバ設定を含みます。実際に試すことによって、設定内容を正しく理解できますので、実環境を使うことをおすすめします。
3.最強Web問題集の問題を解く
最強Web問題集は、下記のようなシステムになっています。
『一度正解』→銀メダル
『連続正解』→金メダル
『失敗』→銅メダル
そのため、各章のパート毎のすべての問題を金メダルにしてください。知識を定着させるために、この作業を2周しましょう。
②Ping-t コマ問で問題を解く
次にコマ問を実施します。上記と同じく1章のパート毎に進めていきます。すべて正解する必要はありませんが、コマンドをタイプする問題に対応するために、8割くらい正解できるように仕上げましょう。
③スピードマスター問題集を解く
最後にスピードマスター問題集で総仕上げをします。下記の教材の各章ごとの問題、まとめ問題を解いてください。私は受験日までにこのまとめ問題を9割取れるように仕上げていました。
リンク
リンク
まとめ
・筆者がLPICを受験するために学習した方法を共有しました。
・Ping-t、スピードマスターは合格のための必需品です。
NWスペシャリスト合格までの流れをまとめました
どうも、こじまるです。
2019年秋のNWスペシャリスト試験を受験し、合格することができました。今後この試験を受験する方の参考となるように、学習の流れをまとめたいと思います。

はじめに
筆者の情報処理技術者試験の取得資格は下記の通りです。
- 応用情報 2018年春期
対象読者
・NWスペシャリストを初めて受験する方
・NWスペシャリストの学習方法を学びたい方
学習内容
基礎学習
NWスペシャリストの特徴といえば、
- 試験範囲が広いこと
- 覚えないといけない用語がたくさんあること
です。筆者もNWスペシャリストの勉強を始めたころは、試験範囲の広さ・量に唖然としました。
NWスペシャリストの学習には、下記教材を使って、ノートに情報をまとめるように学習しました。
2020 ネットワークスペシャリスト 「専門知識+午後問題」の重点対策 (重点対策シリーズ)
NWスペシャリストの機能を覚える時には、機能のメリット・デメリットを意識するようにしてください。なぜなら、出題者は機能のメリット・デメリットに着眼して、設問を作るケースが多いためです。
例えば、POP3のデメリットとしては、
- パスワードが平文で流れること
- ダウンロードするため、複数のPCで同じメールが見れないこと
などが挙げられます。過去問の設問4 (2)では、POP3の問題を記述する設問となっていますが、上記のデメリットの2番がそのまま答えになります。

午後1/午後2対策
過去問対策におすすめの本は何といっても左門さんのネスぺシリーズです。筆者は平成25年度~平成30年度まで購入していました。

筆者は午後1/午後2対策を始めたころ、別の問題集を活用していましたが、解説を読んでも問題や設問の意味が分からないということが多々ありました。ネスぺシリーズは、問題解説と設問解説を図を使って丁寧に説明してくれています。
書籍を購入するとコストはかかりますが、活用すればNWスペシャリストの問題の意味が分かります。問題集を解き始めたが、解説を読んでもわからないという方はぜひご参考に。
ネスぺの剣25 ~ネットワークスペシャリストの最も詳しい過去問解説 (情報処理技術者試験)
ネスペ 27 礎 -ネットワークスペシャリストの最も詳しい過去問解説
ネスペ 29 魂 -ネットワークスペシャリストの最も詳しい過去問解説
ネスペ30 知 -ネットワークスペシャリストの最も詳しい過去問解説
ネスペR1 - 本物のネットワークスペシャリストになるための最も詳しい過去問解説
過去問を解いてみるが、全く点数が伸びない方には下記の書籍をおすすめします。こちらも同じくネスぺシリーズではありますが、平成28年度の過去問解説の代わりにNWスペシャリスト試験に合格するための基礎を学ぶ書籍が発売されています。
NWスペシャリストに限った話ではありませんが、高度試験合格のために最も重要なのは基礎力です。基礎ができていなければ、午後2の応用問題など解けるわけもありません。本書籍では、試験範囲の基礎技術について丁寧に解説してくれています。
")
午前2対策
基礎学習を入念にした場合、午前2の問題は勉強しなくても合格圏内の点数が取れるかもしれません。しかしながら、午前2で足切りされることだけは嫌なので、過去問道場で入念に対策します。
私の場合は、過去10回分くらいを目安に過去問を使って練習を行いました。午前2は、過去問からも出題されます。過去問問題を落とさないようにしっかり学習しました。
情報処理安全確保支援士過去問道場|情報処理安全確保支援士.com (sc-siken.com)
受験結果
午後1はぎりぎりだと思っていましたが、案外点数が取れていました。午後2は個人的に割と簡単な問題だと感じたので、点数も高かったです。

感想
初のスペシャリストの資格として、NWスペシャリストに合格しました。情報処理試験の受験をした頃から、高度区分の合格は一つの目標だったので、合格できて嬉しいですね。